We're building one AI recruiter, one piece at a time
Nova is AI for recruiting. We build the parts of the job that are hardest to build, make each one excellent, then assemble them into a single recruiter that works alongside you.
Nova is AI for recruiting.
We have built the parts of the job that are hardest to build: screening, sourcing, and the rediscovery of candidates a company already has, with outreach and fraud detection alongside them. Each is a real problem that sells on its own. Each one is a piece of one recruiter.
The plan is simple to say and hard to do. Build each piece. Make it excellent. Then put the pieces together as one AI recruiter that works alongside the user.
The moat lives in the harness
The ingredients for an AI recruiter are no longer the scarce part. The models became good enough about a year ago. The search APIs are open. Every competitor, and every recruiting team, has the same ingredients we do.
So why does no recruiter have an AI recruiter yet?
Because the difference lives in the harness: the tools the agent can call, what it sees in context at every step, the subagents it spins up, the search architecture underneath, the evals that hold quality, and the recruiting knowledge encoded into all of it. A harness maps the hundreds of small and large parts of what it takes to be a good recruiter into the system the model works in.
The leverage is measurable. In one internal eval on search quality, a single change to our agent moved the strong-candidate rate from 16% to 69% using the same model. The model did not change. The harness did. That is where the last year went, and none of it is generic engineering: it is recruiting knowledge turned into harness engineering.
And the harness compounds. Every recruiter correction teaches the system what that team means by good. Every failure becomes a regression test drawn from a real production session. Every integration deepens its reach into the real world. The models themselves are no longer the bottleneck.
What the harness looks like, in one module
Take sourcing.
A good recruiter does not start with candidates. They start with a theory of the market. So Nova does too: it takes a role, clarifies the constraints and archetypes, and maps the market before it ranks a single person: which companies produce this talent, which titles hide the same work under different names, which adjacent backgrounds might beat the obvious pool, and which constraints are real versus the first draft of a messy brief.
That is search.
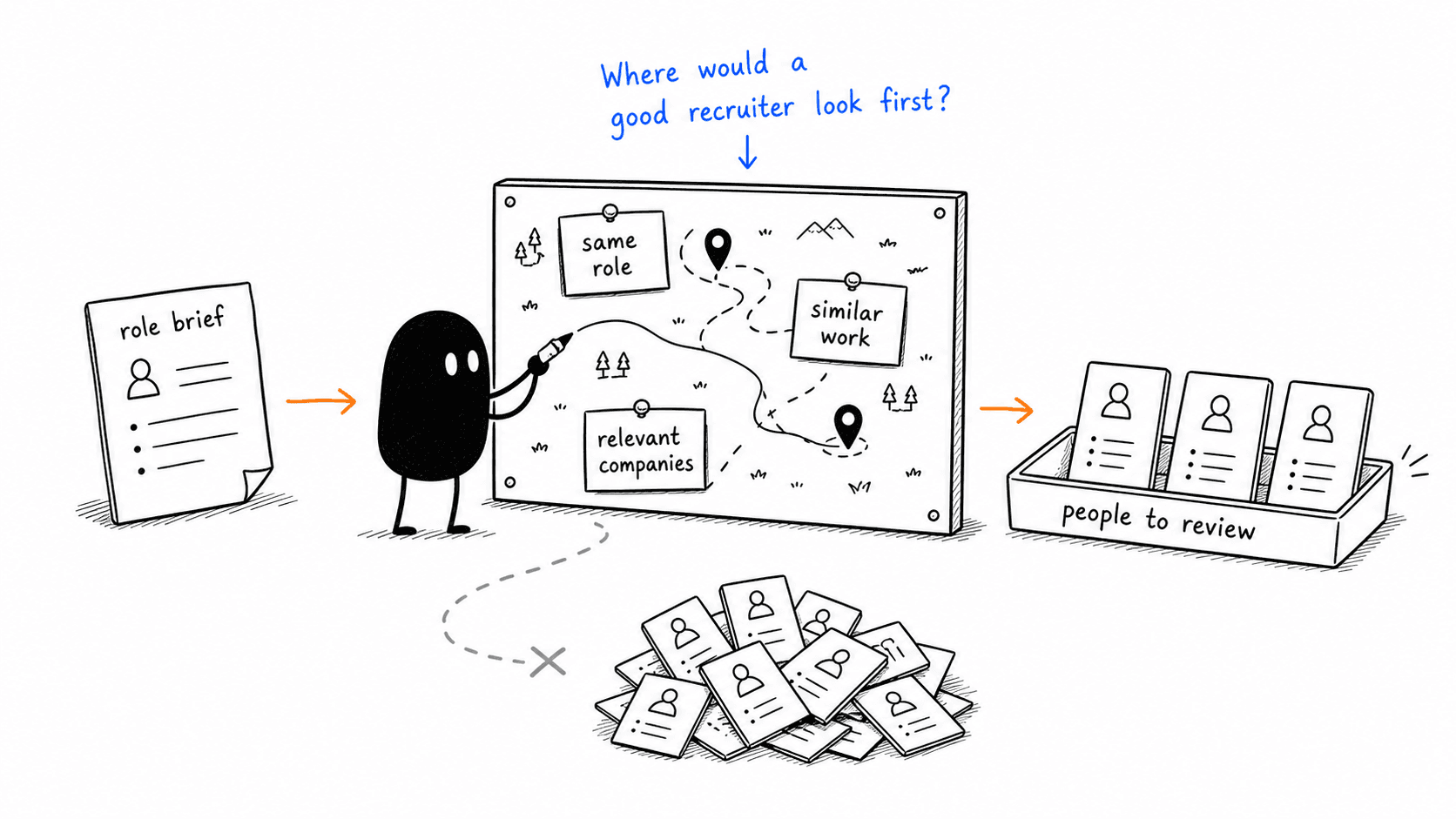
The title is where this bites first. A Forward Deployed Engineer might be called exactly that at one company. Somewhere else the same person is an applied AI engineer, a solutions engineer, a technical founder, or a customer-facing machine learning engineer. The title matters, but the work matters more. So Nova runs several searches, not one: literal title matches in one lane, the same work under different titles in another, alumni of companies known to produce the right people in a third. Each lane tests a different theory and produces a different kind of noise.
Then it does deep research on the people who surface across LinkedIn, GitHub, X, Google Scholar, personal sites, and public writing. It hands back an inspectable verdict instead of a number. A score is seductive because it makes everything feel simple. Scores can carry signal, but they collapse the wrong things. They hide whether a requirement was directly visible or merely inferred, and whether a missing point is fatal, negotiable, or worth asking the hiring manager about.
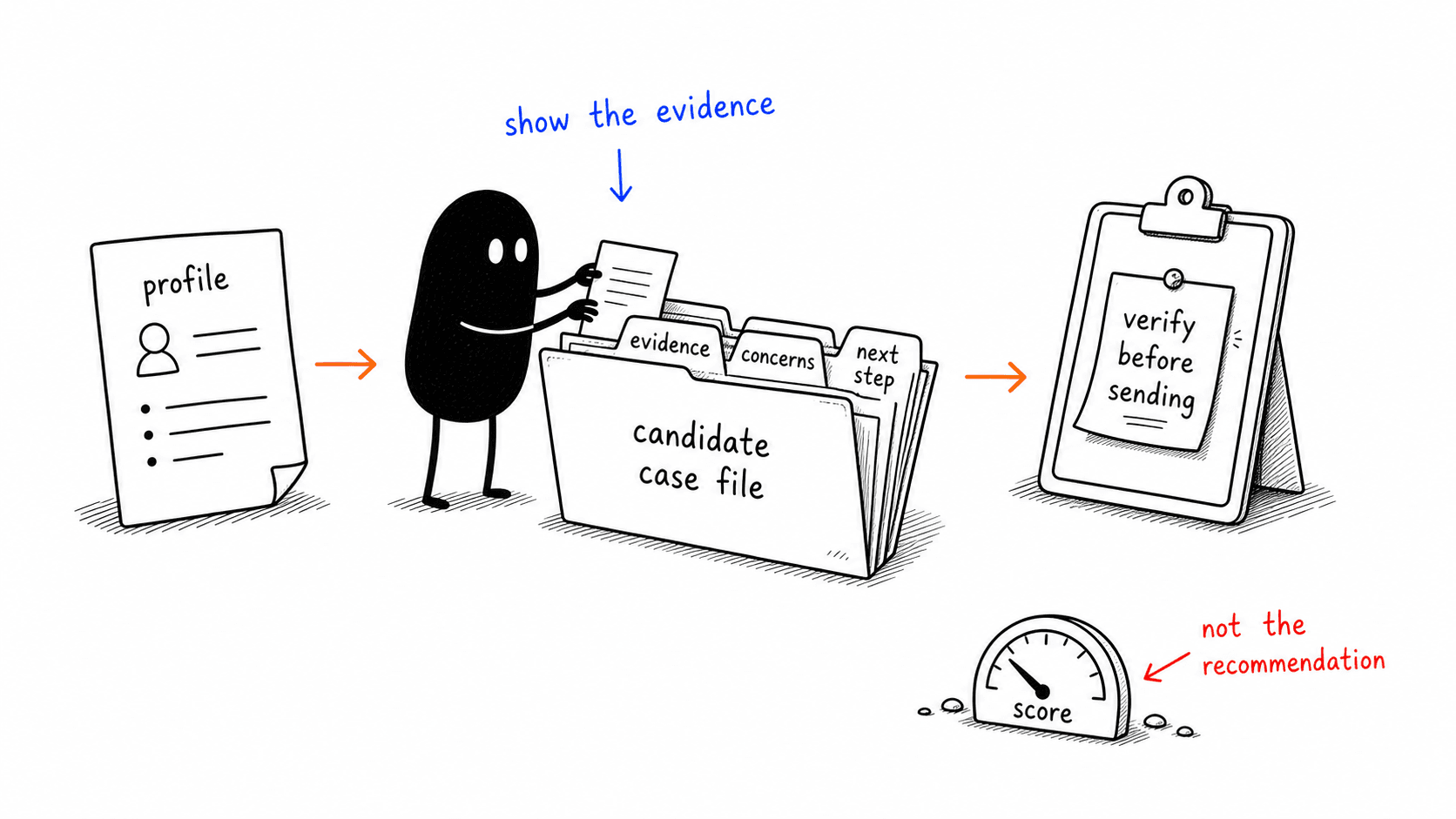
So the output is closer to this: promising, but verify before sending. Relevant product leadership and adjacent payments experience, with a caveat around current remit and location. The next step is to confirm those or ask whether the adjacent background counts for the requirement. That is a different product surface from "7.1 out of 10." One gives the recruiter a number; the other gives them judgement they can inspect.
None of that fits in a single model call, and it does not need to. This is the harness doing its job: the agent can inspect a batch of hundreds of results without pasting every profile into the chat, and remember what a lane learned without replaying the whole lane. The recruiter sees the compact, useful version; the full evidence stays available underneath.
And it learns. Tell it "right background, too academic," and the next search biases toward people who have shipped in production. Feedback changes the search itself, not just a thumbs-up count, so each pass through the market makes the next one sharper.
Every module gets this same treatment. Sourcing is just the one that is easiest to show.
The rest of the recruiter
Screening.Nova calibrates the role criteria with the recruiter and hiring manager, then scores every inbound applicant against them, the work that swallows a recruiter's week when hundreds of applications land. Each score carries its evidence: why the candidate fits, what is missing, and what to ask in the next interview. It plugs into the applicant tracking systems (ATS) recruiters already use. Pinpoint, a major ATS with millions of applications flowing through it each month, chose Nova over the alternatives it tested, and runs its inbound scoring through our API. That puts Nova inside the system recruiters already work in.
Talent rediscovery.Most companies already know more relevant candidates than they can use: past applicants, silver medalists, late-stage rejects, referrals. The ATS freezes them at the moment they applied; someone too junior two years ago may be right now. Existing ATS search matches old records on keywords and cannot tell what changed, why someone was rejected, or whether they now fit the live role. Nova searches the whole history: notes, interview feedback, stages, rejection reasons. It refreshes the evidence for the people who matter, and explains why someone is worth another look now. The first search should often be inside the company's own history, not outside on LinkedIn.
Outreach. Downstream of search. Once Nova has found and researched someone, it drafts and sends messages across LinkedIn, email, and SMS, grounded in that research: why this person, why this role, what to say. Most AI outreach is slop the best candidates ignore, because the tool knows nothing about who it is messaging. Ours does.
Fraud detection. Nova flags candidates whose history does not hold up, which matters more as AI-generated applications rise.
Where this is going
The end state is one AI recruiter.
It takes a role and grills the hiring manager on what actually matters. It researches the market and comes back with what is realistic and what the constraints are. It iterates on the requirements with the user until the ideal profile is clear. Then it finds the candidates, researches each one, reaches out, works out who is relevant and interested, and screens them. Where the CV and the online profile leave gaps, it interviews the candidate to fill them. It runs inbound applications through the same process. What lands on the recruiter's desk is a short list of people who are real, qualified, and interested, with the evidence attached and the meetings booked.
Every step of that is a module. We build one piece at a time and make it excellent before moving to the next. The pieces above are the first five.
We will not get there by going fully autonomous today. We built the autonomous version first, and it lost to a recruiter using good tools. A human pass on the shortlist made the results dramatically better. So the agent takes on more of the job as each piece proves reliable, and the human keeps trust, persuasion, and the final call.
Andreas Asprou
Co-founder & CTO, Nova